単純作業の効用は意外と大きい

owという、TypeScriptの型制限を拡張したOSSに何度かコミットして気づいたことは、単純作業は意外と効用が大きいということだ。
github.com
具体的に何をしたかというと、typescript-eslintの、explicit-function-return-typeが無効になっていたのを、有効にした。
github.com
まずはじめにpackage.jsonのexplicit-function-return-typeの設定を"off"から"error"に変更し、テストを走らせた。
https://github.com/sindresorhus/ow/pull/206/files#diff-7ae45ad102eab3b6d7e7896acd08c427a9b25b346470d7bc6507b6481575d519R89
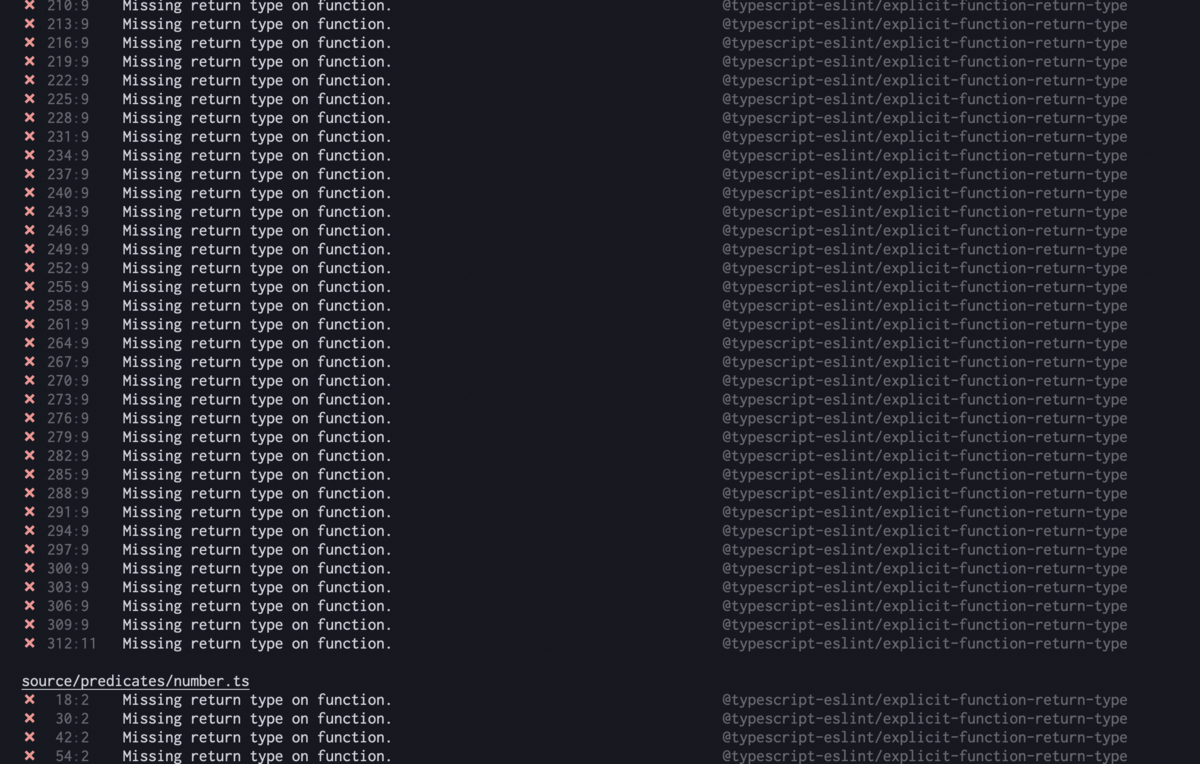
あとは、そのテストが落ちた箇所にひたすら型をつけていった。
この型づけは自分的には単純作業のうちに入るのだが、自分のスキルはそれほど伸びないものの、得られる効用は大きい。
ほんの30分の型づけにより、これからこのOSSにコミットする全ての人は、function return type をつけなければならなくなった(つけないとテストが落ちる)。
これは、このOSSの保守性に直結することである。
関数が返す型が明確になると、初めてこのOSSに訪れる人のコードリーディングが捗るというオプションもついてくる。
このように、O(1)の単純作業でO(N)の効用が得られる。
ただし、個人的にはこのexplicit-function-return-typeを有効にするには然るべきタイミングがあると思っている。
まず、プロジェクトの初期からこれを有効にすると、テストが高確率で落ちることになり、開発スピードが落ちてしまう。
また、explicit-function-return-typeを有効にするときに、他のPRが溜まっている状態だったら、凄まじいコンフリクトが生じてしまう。
https://github.com/sindresorhus/ow/commits/main
なので、今回は、OSSとしてある程度枯れていること、他の人とPRが被らない時期であることを確認してから、このPRを出した。
ちなみにこういった単純作業をするときは、ミスチルの彩りを聴きながらすると捗る。
Cypress で `blitz new` をテストしたい(が、できていない)

ことの発端は、最近よくBlitzを聞くようになり、GitHubを訪れると、good first issueが転がっていて、テストに関するものがあったので、Blitzを触ったことも、GraphQLやPrismaもあまり知らなかったけど、拾ってみた。
このissueの内容は、blitz newの挙動をCypressを使って確かめたい、というものだった。
Add e2e CLI test for `blitz new` · Issue #37 · blitz-js/legacy-framework · GitHub
We currently have a few blitz new tests, but not a complete e2e test for the new app.
...
Add Cypress to our CLI testing setup. See the Redwood CLI cypress test for a great example/starting point.
Cypressもはじめて聞く名前だったが、ドキュメントを読んでちょっと手元で動かして何となく理解し、Blitzに導入することにした。
(Cypress導入第1人者かと思っていたが、先人がいた)
マージされてコントリビューターにもなれたので、本腰をいれてテストを増やしていこうと思ったのだが、Blitzレポジトリの中でblitz newをe2eテストする、ということがよくわからなくなってしまった。
blitzを試すために手元でblitz newしたレポジトリも作って触っていて、どっちで何をしたいのかわからなくなり混乱が加速した。
なので、issueのなかで言及されていた、Redwoodのe2eテストがどうなっているのかを見にいくことにした。
まずは、RedwoodのCONTRIBUTING.mdを読み、e2eテストを動かすことにした。
が、うまく動かなかったのでissueを出した。
すると、2日足らずで問題は解決したようで、Cypressに慣れるためにも新たにテストを追加した。
Cypressは完全に理解できたので、Blitzにも入れていきたいが、Blitzレポジトリの中でblitz newをe2eテストするということがよくわからい問題が健在している。
Redwoodでは、起点がシェルスクリプトで、"We will copy './packages/create-redwood-app/template' and the packages/*"していることがわかっている。
redwood/test-tutorial at d61734296bf843d50933d36cabb2a9ea25ede919 · redwoodjs/redwood · GitHub
だが、Blitzに'./packages/create-redwood-app/template'に当たるものがあるとは思えない。
また、これと同じようにシェルスクリプトで起動するとしても、Blitzの場合はデフォルトのフォームを選択する部分があり、そこをどうモックしたらよいのかわからない問題もある。
blitz/new.ts at e2383fbb5f52a59042640dcf4cb67d2c8344de06 · blitz-js/blitz · GitHub
Blitz既存のnew.test.tsを見にいったところ、mockImplementationでモックしていることがわかったが、これはあくまでcliのテストなのでやりたいこととは違う。
jest.mock("enquirer", () => { return jest.fn().mockImplementation(() => { return { prompt: jest.fn().mockImplementation(() => ({form: "React Final Form"})), } }) })
詰まってしまったので、そもそもblitz newコマンドを打ったら、どのようにしてファイル群を生成しているのかを見に行ったら、ヒントがあるのではないかと思い読み始めた。
すると、new.tsでは、generatorを生成してそれを走らせているっぽいことがわかった。
blitz/new.ts at e2383fbb5f52a59042640dcf4cb67d2c8344de06 · blitz-js/blitz · GitHub
blitz/new.ts at e2383fbb5f52a59042640dcf4cb67d2c8344de06 · blitz-js/blitz · GitHub
const generator = new (require("@blitzjs/generator").AppGenerator)({ ... await generator.run()
blitz newのテストは実質的にはgeneratorのテストなのか?、ということで"@blitzjs/generator"を読みにいこうとしたところで力尽きている。
exmapleにすでにテストがあるのでそれでいいのではないかと思い始めているけど、勉強になりそうなのでちょっとづつ読んでいきたいと思っている。
https://github.com/blitz-js/blitz/blob/canary/examples/auth/cypress/integration/index.test.ts
2/19追記
was this issue resolved in #1846?
という質問が来ていたので、疑問点をissueに書き込んでおいた。
https://github.com/blitz-js/blitz/issues/1767#issuecomment-781707012
NTT Performance Tuning Contest の対策と反省と抱負
今までISUCONのようなパフォーマンスチューニングのイベントには参加したことがなかったのですが、興味はありました。
23卒があつまっているSlackで参加したいとつぶやくと、一瞬で反応が返ってきてチームを組めることになり、@PANORAMA_01さんと@marin_a___さんで参加しました。
大学ではHello Worldしないのでこういうコミュニティありがたいです。
対策
言語はRubyを選んでいたので、Sinatra でくるだろうと思い、チュートリアルを軽く眺めてget, postの挙動を確かめたりしました。
Rubyの文法を忘れている部分があったのでちょっと復習しました。
qiita.com
パフォーマンスチューニングの雰囲気を掴むために過去開催されていたブログを読みました。
www.ntt.com
isucon.net
N+1問題について調べました。
Nは発行したクエリの数であり、探索したレコードの数ではないことを知り理解がクリアになりました。
qiita.com
qiita.com
インデックスとEXPLAINコマンドについて復習しました。
dev.mysql.com
qiita.com
blog.utgw.net
Nginxを調べて、リバースプロキシやキャッシュの設定を試しました。
proxy · wafuwafu13/sinatra-tutarial@fc25c4e · GitHub
画像キャッシュの設定 · wafuwafu13/sinatra-tutarial@8218b11 · GitHub
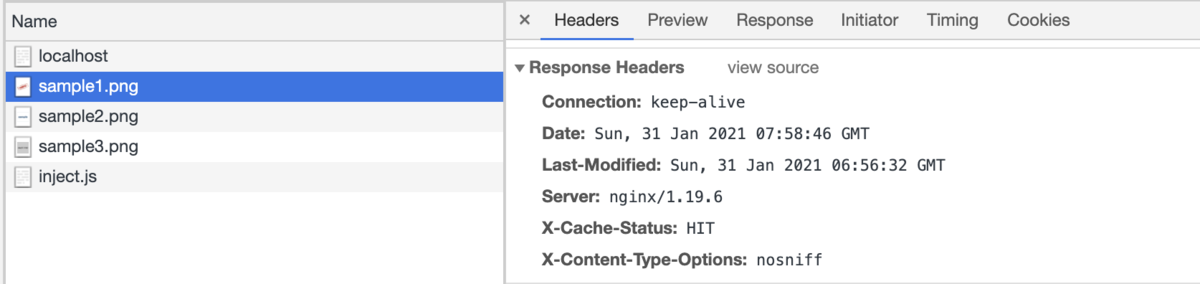

qiita.com
rin-ka.net
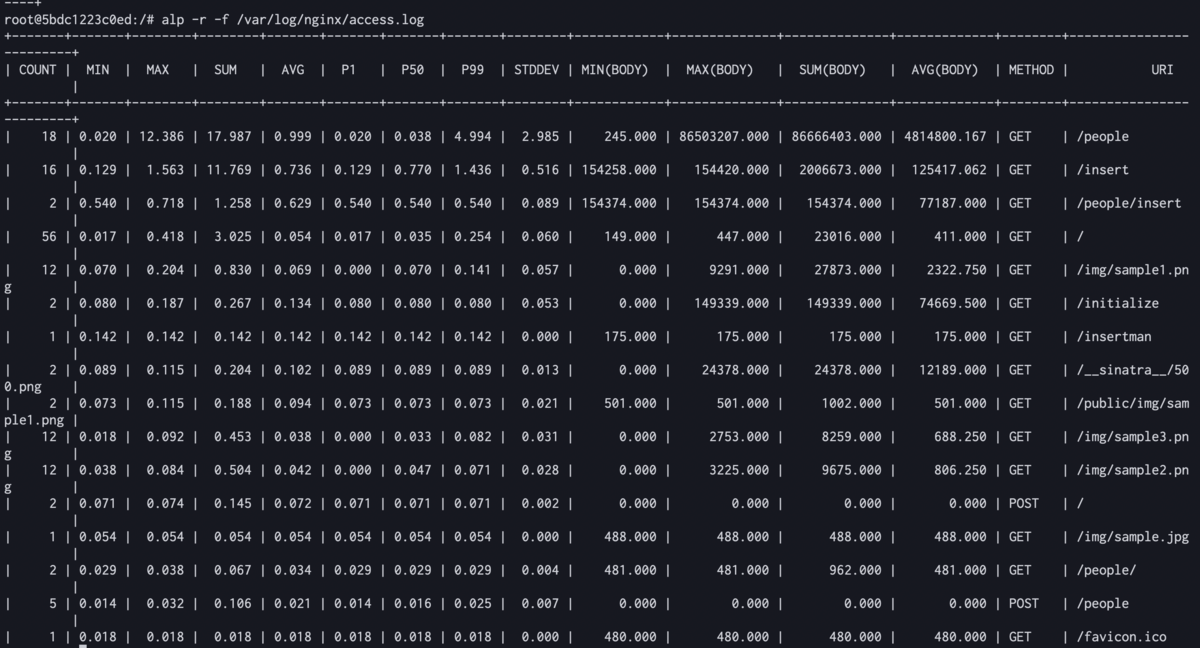
alpについて調べて試しました。
logをマウント · wafuwafu13/sinatra-tutarial@f49103e · GitHub
MySQLのスロークエリの設定やpt-query-digestについて調べて試しました。
pt-query-digest · Issue #1 · wafuwafu13/sinatra-tutarial · GitHub
masayuki14.hatenablog.com
thinkit.co.jp
dtyler.io
ISUCONのススメが前日に発売開始されていたので眺めました。
nextpublishing.jp
本番に向けて3人で勉強の進捗確認とか作戦会議をしました。
3人ともフロント寄りというかアプリケーションのコードを書いているのでゆるくがんばろうというモチベーションで参加しました。
反省と抱負
本番は、pt-query-digest入れて実行してスロークエリ見つけてインデックスをはってN+1を見つけて解決策がわからず放置してalpつかおうと思ってNginx入れようとしてわからなくなって放置して画像カラムどうにかしようとして解決策がわからなくなって放置して終了しました。
ベストプラクティスを脳に詰め込んでいっても手は動かないことを実感した7時間でした。
個々の使い方やボトルネックは分かるけど本番のアプリケーションにうまく落とし込めないのが放置して終了の原因だと思われます。
個々のアルゴリズムはわかるけど問題が解けない競プロと同じ感じがしています。
自分たちで本番と同じような環境を構築して経験を積んでコンテストに出ないと足元にもおよばないので練習あるのみという感じです。
ただ、今回参加に向けて勉強したり本番でできたりできなかったりした知見は結構大きいなと思っています。
あとは言語ですね、今回はRubyを使用しましたがパフォチューにはGoという感じがしているのでつめていきたいです。
言語やその周辺ライブラリの習得には、文法を理解する、自分でアプリケーションを作る、現場で使う、OSSを読んでPRする、の4段階あると思っています。
JS/TSは、現場で使う、OSSで生かす、OSSで学ぶ、現場で生かすのブーストが(たぶん)かかっている状態なので半年〜1年間でGoやその周辺ライブラリもそこまで持っていきたいと思います。
NTTさん、チームのかた、ありがとうございました!!
リベンジしたい!!!
「関数型プログラミングの基礎」モナドを作るを理解する
と同じ本の、p.268~p.274あたりでつまずいたので、メモを残しておく。
コードはここにおいてある。
akimichi.github.io
モナドの機能は、「値にコンテキストを付加すること」、「コンテキストを付加したまま処理を合成すること」である。
unit関数は、モナドのインスタンスを生成するための関数で、unit:: T => M[T]という型情報を持つ。
Tはモナドに渡される値の型であり、Mはモナドの型である。
flatMap関数は、処理を合成するための関数で、flatMap:: M[T] => FUN[T => M[S]] => M[S]という型情報を持つ。
M[T]というモナドのインスタンスを受け取ると、そのモナドから値を取り出してT => M[S]という関数を適用し、その結果としてM[S]を返す。
今回メモするモナドは、恒等モナドである。
恒等モナドは、値にコンテキストを付加することなく、そのまま値として扱う。
恒等モナドの関数を、以下のようにIDという名前空間に定義する。
const ID = { unit: (value) => { return value; }, flatMap: (instanceM) => { return (transform) => { return transform(instanceM); }; }, };
また、次のような関数を定義する。
const succ = (n) => { return n + 1; }; const double = (m) => { return m * 2; };
unit関数は、単に値を返しているだけである。
ID.unit(1) == 1;
flatMap関数を介して1にsucc関数を適用する処理は、succ(1)と同じ結果になる。
ID.flatMap(ID.unit(1))((one) => { return ID.unit(succ(one)); }) == succ(1)
これを順を追ってみていく。
まず、ID.flatMapは、引数ID.unit(1) = 1なので、以下を返す。
(transform) => { return transform(1); };
そして、(one) => { return ID.unit(succ(one)); }が適用される。
(one) => { return ID.unit(succ(one)); }(1)
よって元のモナドは、succ(1)と同じ結果になる。
次に、flatMap関数を入れ子にしたものをみていく。
これは、次の関数を合成する関数をおなじ働きをする。
const compose = (f, g) => { return (arg) => { return f(g(arg)); }; };
つまり、以下の等式が成り立つ。
ID.flatMap(ID.unit(1))((one) => { return ID.flatMap(ID.unit(succ(one)))((two) => { return ID.unit(double(two)) }) }) == compose(double, succ)(1)
これを順を追ってみていく。
まず、以下の関数に着目する。
ID.flatMap(ID.unit(succ(one)))((two) => { return ID.unit(double(two)) })
ID.flatMapは以下を返す。
(transform) => { return transform(ID.unit(succ(one))); };
そして、(two) => { return ID.unit(double(two)) }が適用される。
((two) => { return ID.unit(double(two)) })(ID.unit(succ(one)))
よって、元の以下の関数は、
ID.flatMap(ID.unit(1))((one) => { return ID.flatMap(ID.unit(succ(one)))((two) => { return ID.unit(double(two)) }) })
以下のようになる。
ID.flatMap(ID.unit(1))((one) => { return ((two) => { return ID.unit(double(two)) })(ID.unit(succ(one))) })
ID.flatMapは、引数ID.unit(1) = 1なので、以下を返す。
(transform) => { return transform(1); };
よって、以下の関数が適用されると、
(one) => { return ((two) => { return ID.unit(double(two)) })(ID.unit(succ(one))) }
最終的には以下のようになる。
(one) => { return ((two) => { return ID.unit(double(two)) })(ID.unit(succ(one))) }(1)
よって元のモナドは、関数を合成する関数と同じ働きをする。
const compose = (f, g) => { return (arg) => { return f(g(arg)) } } ID.flatMap(ID.unit(1))((one) => { return ID.flatMap(ID.unit(succ(one)))((two) => { return ID.unit(double(two)) }) }) == compose(double, succ)(1)
GoでPythonのrandom.shuffle()を実装し、カイ二乗検定を用いたユニットテストをする
背景
Goでコントリビュートできそうなレポジトリを探していると、goshというレポジトリがあった。
これは、JavaScriptやPythonでの構文をGoで書く、というものだった。
面白そうだったので、Pythonのshuffleを実装し、PRを出そうと思った。
Pythonのshuffleというのは、配列を受け取り、その配列の要素の順番をランダムに変換して返す、というのだった。
commitしようとしていたコードは、以下だった。
func Shuffle(s []interface{}) []interface{} { rand.Seed(time.Now().UnixNano()) rand.Shuffle(len(s), func(i, j int) { s[i], s[j] = s[j], s[i] }) return s }
しかし、commitしようとした時にはもう実装されていたのでissueを閉じた。
github.com
commitしようとした時のテストコードは、
- shuffleする前とした後で配列の長さが等しい
- shuffleする前とした後で配列の要素が等しい
ことを確認するものだった。
しかしよく考えると、上のコードでは破壊的な操作はしておらず、上記の2項目は自明であった。
肝心なのは、
- shuffleによって、要素の順番が満遍なく変換されている
ことを確認することだった。
今回のような、ランダム性をテストする時にはどうしたらよいかを調べてみると、以下のスライドがあった。
speakerdeck.com
このスライドによると、カイ二乗検定によってランダム性をテストできる、ということだった。
カイ二乗検定とは
帰無仮説が正しければ検定統計量が漸近的にカイ二乗分布に従うような統計的検定法の総称である。
カイ二乗検定 - Wikipedia
ざっくりとした感じで例を出す。
サイコロを振って、目が均等に出ているかどうかを検定したいとする。
実際に振ってみて出た目の回数を観測度数、目が均等に出ている場合の回数を期待度数という。
それぞれの回数が以下の場合、
| サイコロの目 | 1 | 2 | 3 | 4 | 5 | 6 | 合計 |
|---|---|---|---|---|---|---|---|
| 観測度数 | 17 | 22 | 21 | 14 | 22 | 24 | 120 |
| 期待度数 | 20 | 20 | 20 | 20 | 20 | 20 | 120 |
という計算でを求める。
このが、棄却域より小さければ、目が均等に出ていることが保証される。
棄却域は有意水準と自由度で決まる。
有意水準は、たいてい5%か1%で、自由度は、(要素の数 - 1)で、今回だったら、(目の数6 - 1 )= 5となる。
棄却域の分布表は以下から取得できる。
http://www3.u-toyama.ac.jp/kkarato/2016/statistics/handout/chisqdist.pdf
コードの概要
今回作ったリポジトリが以下である。
github.com
shuffle.goには、先述したshuffleのコードを書いている。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/shuffle.go
package chi_square import ( "math/rand" "time" ) func Shuffle(s []interface{}) []interface{} { rand.Seed(time.Now().UnixNano()) rand.Shuffle(len(s), func(i, j int) { s[i], s[j] = s[j], s[i] }) return s }
テストは、[]interface{}{"a", "b", "c", "d", "e"}というスライスをShuffleに渡したとき、うまくシャッフルできているかを確認する。
カイ二乗検定を行うChiSquareは、第1引数に有意水準、第2引数に自由度、第3引数に観測度数、第4引数に期待度数をとり、が棄却域より小さい場合に
true、大きい場合にfalseを返している。
Shuffleを100回実行したとき、スライスの先頭、つまり"a"の位置が、0,1,2,3,4番目にくる回数がそれぞれ等しかったら、うまくシャッフルできているといえる。
よって、期待度数は、[]float64{20, 20, 20, 20, 20}となる。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/shuffle_test.go#L28
観測度数は、実際にShuffleを100回実行し、"a"のインデックスを累計して求めている。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/shuffle_test.go#L27
有意水準は5%に設定し、自由度は(配列の長さ-1)で求められている。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/shuffle_test.go#L29
if !ChiSquare(5, len(expected_frequency)-1, observation_frequency, expected_frequency) { t.Error("not shuffled") }
の計算および、棄却域との比較は、
chi_square.goでやっている。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/chi_square.go
... x += (math.Pow(observation_frequency[i] - expected_frequency[i], 2)) / expected_frequency[i] ... if x > rejection_area { return false } else { return true } ...
テスト実行と結果
実際にテストを実行してみると、以下のような出力を得る。
https://github.com/wafuwafu13/go-chi-square-test/blob/master/chi_square.go#L14
$ go test x: 1.0999999999999999, rejection_area: 9.49 PASS ok go-chi-square-test 0.474s
の値、つまり出力
xの値は実行するたびに異なる。
このことからもシャッフルがうまく行われていることがわかる。
< go test x: 4.1, rejection_area: 9.49 PASS ok go-chi-square-test 0.148s
また、shuffle.goのrand.Seed(time.Now().UnixNano())の処理を消すと、出力xの値は実行するたびに同じになり、(テストの結果をログに残しておけば?)シャッフルの処理がうまく行われていないこともわかる。
ちなみに、テスト対象のスライスを[]interface{}{"a", "a", "a", "a", "a"}にすると、毎回"a"が0番目にあると判定されてしまうので、テストは落ちる。(そもそも同じ要素だけのスライスをshuffleする動機が謎なので落ちて正解という捉え方もできる)
https://github.com/wafuwafu13/go-chi-square-test/blob/master/shuffle_test.go#L9
$ go test x: 400, rejection_area: 9.49 --- FAIL: TestShuffle (0.00s) shuffle_test.go:30: not shuffled FAIL exit status 1 FAIL go-chi-square-test 0.414s
テスト対象のスライスによってexpected_frequencyの値を変えてTableDrivenTestsすればよいと思うけど、もう満足したので終わる。
数学3の教科書をSymPyで解く
自然言語処理に興味を持っている。
wafuwafu13.hatenadiary.com
が、本を読んでいても数式が結構出てきてきついところがあった。
数1と数2はかろうじて履修していたが、数3からは全くわからず、∞とかがでてくると拒否反応を示すレベルだった。
だからまず数学に入門することにした。

この本でSympyを知り、せっかくだから積読していた数3の教科書を解いてみることにした。

Sympyは、あくまで理解の補助として簡単な問題で使い、他の問題は途中式まで理解することを意識した。
とりあえず微分が理解できればよさそうだったので、3章の関数と極限と、4章の微分法とその応用までやった。
この資料もまとまっていてよかった
解いたのがこちら。
giste5ab71750d08bb4af1ad01eb5dd3200a
とりあえず数式に拒否反応はなくなったのでよかった。
「関数型プログラミングの基礎」代数的データ構造とパターンマッチを理解する

この本で関数型プログラミングの基礎を押さえようとしたけれど、p140の「代数的データ構造とパターンマッチ」あたりから理解に苦しんだのでメモをとりながらじっくり進めることにした。
全てのコードはここに置いてある。
akimichi.github.io
JavaScriptのswitch文では、配列のように可変なデータの場合にはアドレス値で比較されるので、マッチングは失敗する。
以下が良い例である。

よって、複数の選択肢からいずれか1つの型だけを選ぶデータ構造である代数的データ構造を使ってマッチングを行う。
代数的データ構造は、以下のように具体的なデータは作らず、(pattern) => return pattern.XXXという関数を返す。
const empty = () => { return (pattern) => { return pattern.empty(); }; }; const cons = (value, list) => { return (pattern) => { return pattern.cons(value, list); }; };
パターンマッチを実行するmatch関数の引数のdataには代数的データ構造、patternにはオブジェクト型のインスタンスが入る。
このインスタンスによって条件分岐を実行する。
const match = (data, pattern) => { return data(pattern); };
代数的データ構造のリストに対するisEmptyをmatch関数を利用して実装する。
isEmptyは、引数に渡されたリストが空のリストかどうかを判定する。
const isEmpty = (alist) => { return match(alist, { empty: () => { return true; }, cons: (head, tail) => { return false; }, }); };
実際に使ってみると以下のようになる。
isEmpty(empty()); // true isEmpty(cons(1, empty())) // false
1つ目のisEmpty(empty())から詳しく読む。
isEmptyの引数およびmatchの第一引数であるdataとなるempty()は以下の関数を返す。
(pattern) => { return pattern.empty(); };
また、patternは以下のオブジェクトである。
{ empty: () => { return true; }, cons: (head, tail) => { return false; }, }
よって、matchではpatternのemptyが実行され、trueが返る。
同じようにisEmpty(cons(1, empty()))を読んでいく。
consの定義をもう一度みてみると、以下である。
const cons = (value, list) => { return (pattern) => { return pattern.cons(value, list); }; };
よって、isEmptyの引数およびmatchの第一引数であるdataとなるcons(1, empty())は以下の関数を返す。
(pattern) => { return pattern.cons(1, (pattern) => { return pattern.empty(); } ); };
よって、patternのconsが実行され、falseが返る。
次に、リストの先頭要素を調べるheadの定義を読む。
const head = (alist) => { return match(alist, { empty: () => { return null; }, cons: (head, tail) => { return head; }, }); };
実際に使ってみると以下のようになる。
head(cons(1, empty())) // 1
これは、引数は同じだが、patternのconsは以下のように第一引数のheadを返す。
{ empty: () => { return null; }, cons: (head, tail) => { return head; } }
よって、1が返される。
これで代数的データ構造とパターンマッチは理解できた。
せっかくなのでTypeScriptを使用して型をつけていく。
まずは、完成した型の全体像が以下である。
type IsEmptyPattern = { empty: () => boolean; cons: (head: number, tail: EmptyReturn | ConsReturn) => boolean; }; type HeadPattern = { empty: () => null; cons: (head: number, tail: EmptyReturn | ConsReturn) => number; }; type isEmptyReturn = ReturnType<typeof isEmpty>; type headReturn = ReturnType<typeof head>; type EmptyReturn = ReturnType<typeof empty>; type ConsReturn = ReturnType<typeof cons>; const empty = (): (( pattern: IsEmptyPattern | HeadPattern ) => boolean | null) => { return (pattern: IsEmptyPattern | HeadPattern) => { return pattern.empty(); }; }; const cons = ( value: number, list: | EmptyReturn | ((pattern: IsEmptyPattern | HeadPattern) => boolean | number) ): ((pattern: IsEmptyPattern | HeadPattern) => boolean | number) => { return (pattern: IsEmptyPattern | HeadPattern) => { return pattern.cons(value, list); }; }; const match = ( data: EmptyReturn | ConsReturn, pattern: IsEmptyPattern | HeadPattern ): boolean | null | number => { return data(pattern); }; const isEmpty = (alist: EmptyReturn | ConsReturn): boolean => { return <boolean>match(alist, { empty: () => { return true; }, cons: (head: number, tail: EmptyReturn | ConsReturn) => { return false; }, }); }; const head = (alist: EmptyReturn | ConsReturn): null | number => { return <null | number>match(alist, { empty: () => { return null; }, cons: (head, tail) => { return head; }, }); }; isEmpty(empty()); // ture isEmpty(cons(1, empty())); // false head(cons(1, empty())); // 1
isEmpty、head関数で使われているpatternの型を定義する。
また、empty、cons、isEmpty、head関数の戻り値をReturnTypeでとっている。
isEmpty、head関数の戻り値にType assertionsをつけているのは、以下のようなエラーが出たので誤魔化した。
Type 'number | boolean | null' is not assignable to type 'boolean'.
Type 'null' is not assignable to type 'boolean'.
consの第二引数listの型は、EmptyReturn | ConsReturnにしたらType alias 'ConsReturn' circularly references itself.のエラーが出たので自己参照しないようにした。
Type alias circularly references itself · Issue #14174 · microsoft/TypeScript · GitHub
この辺りで議論されているけど力尽きたのでとりあえずこのままにしておく。
この先もサンクを無限を表現するとか難しそうな項目があるのでじっくり進めていきたい。